Pandas 备忘笔记(一)
Pandas 比Excel 等传统的办公表格软件跟适合用来做数据分析,毕竟Pandas 专注于此。Pandas 入门很简单,但是官方的教程很难满足工作的需要。每次有数据分析需求时,会浪费不少时间,尤其是对我这种不是专门搞数据分析的人来说。趁这次不怎么忙,把自己经常忘记的功能做个笔记。
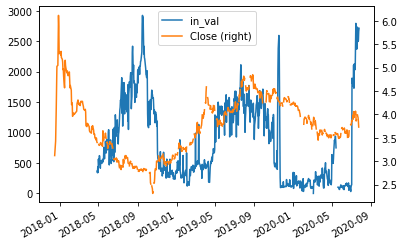
下面代码的功能是:读取并处理云南省近两年的水文记录,并画出水文记录和华能水电股票的价格走势。客户需要根据此图来初步估计水文信息对水电股的价格影响。
hnsd_df = pd.read_csv('华能水电站.csv')
#默认是utf-8 编码
df = pd.read_csv('云南水位数据集.csv', encoding='ansi')
#只保留需要的列
# df1=df[['name', 'time' , 'val', 'in_val', 'out_val']]
# 或者
df = df.loc[:,['name', 'time' , 'val', 'in_val', 'out_val']]
#按某列的内容来筛选行,只保留华能水电的电站,删除不在hnsd_df 的行
df = df[df['name'].isin(hnsd_df['名称'])]
#去除重复记录,指定使用哪几列来确认是否重复
df = df.drop_duplicates(subset=['time', 'name'])
#透视表,把某列的值域的每一个元素转换为列名,values指定要统计的内容
df = df.pivot(index='time', columns='name', values=['val','in_val','out_val'])
df.index=df.index.astype('datetime64[ns]')
# 按天分组 一个电站每天可能有多条不同时间的水文记录
# 采用mean 求平均值
grouped = df.groupby(df.index.date).mean().groupby(axis=1,level=0)
# 对全部电站的水文记录的每天的平均值按发电机组容量求加权平均值
grouped = grouped.agg(lambda x:
np.average(np.ma.masked_array(x, np.isnan(x)),
axis=1,
weights=list(map(lambda y:hnsd_df[hnsd_df['名称']==y].iloc[0,2],x.columns.get_level_values(1)))))
grouped.index=grouped.index.astype('datetime64[ns]')
price_df = tdx.读取日线数据(r'C:\zd_gszq\vipdoc\sh\lday\sh600025.day')
final_df = pd.concat([grouped, price_df], axis=1, sort=False)
#final_df = final_df.dropna()
# 绘制水位于股价的走势图
#final_df.in_val.plot()
#final_df.Close.plot(secondary_y=True, style='g')
final_df[['in_val','Close']].plot(secondary_y=['Close'])
生成的走势图如下: